



Unlike the other blogs I’ve written, this will be very non-technical. It is a sneak peek inside the mind/life of a so called Data Scientist, so pour yourself a cup of coffee and sit back. Why am I writing this? First, I have so much to share regarding my personal journey in this field so far, which I hope at least some of you can relate to. For me this article serves as a self-reflection account, which I’ll probably laugh at someday. Second, I love writing. Now you won’t be able to say that from my public writing history so far. That’s because, I am a master procrastinator and like most of you reading this I hesitate sharing such a personal account publicly, it feels vain to an extent.
But today, I said, what the heck? Later, I’ll tell you the reason why.
The rant will continue a little more, before I actually start the blog. The other reason why writing is so hard, is because I live in an Indian household. It’s a Saturday morning. After spending an hour thinking about what to do with my time, I read Chip Huyen’s article and got inspired. Now, as I sit on my desk near the window, landing heavy strokes on my laptop keyboard, looking at the swinging trees outside my window, trying to feel like a writer, I hear people from my family screaming my name from the other room(because that’s how we talk). I know my sister, being the curious George of the family(to put it mildly), thinking why I haven’t been replying will come to my room, and finding me fervently typing would steal a peek at my screen. So, I’ve been atl+tabing to switch windows, every time I hear footsteps. I wish we lived in the world, that Cal Newport describes in Deep Work and could just go to a cabin in the woods, to think and write.
To give you a little background on myself, I did my engineering from a government university where the education system is better not talked about. Long story short, when the system fails you, you start to look out for yourself. That’s when I found machine learning. Contrary to mainstream tech where we decide each and every aspect of the program, ML only required us to tell the “what” and not the “how”. You could teach a machine how to learn, that was fascinating! Also, I liked the non-deterministic nature of the process, the randomness. The second time you run the same algorithm on the data, it might uncover something different(assuming you are not setting a seed). So, I did what most of us do, took up online courses/ read blogs. After some time, I stumbled upon what could be called the best platform for people learning to work with data, Kaggle.
Becoming a Notebooks Master
The best part about Kaggle is the community and their reward system. You could always find something to learn on it, no matter at what point you are in your data journey. If you haven’t heard of this before, just look at the blogs submitted for the Kaggle DS/ML survey each year. When you share something, there are always people to encourage and help you. If you start spending some time on the platform, it’s reward system of medals and tiers would drive your dopamine and motivate you to get better and work harder. Don’t get me wrong on this, but some people have also gamified this reward system, to climb the ladder. It is the two sides of the same coin. As a side effect, it can demotivate the honest seekers since the ranks/tiers do not hold the same value now.
Last year in May, after being on and off on Kaggle for more than 3 years, I became a Kaggle Notebooks Master. I know it’s not that big of an achievement anymore and a lot of people would do it in much lesser time, but personally, it felt like a milestone. I published notebooks only on topics that challenged me to learn, while also trying to maintain a good account of my learning so that people reading it could benefit from it. Also, on Kaggle, I like reading research papers and trying out different solutions for competitions, but that does not guarantee that I won’t get stuck or would be able to come-up with a solution within the constraints of the notebook environment or not get demotivated and leave it mid-way. My private notebooks bear a witness to this. Yet, slowly I felt I reached a small landmark.
My first break
My work on Kaggle and some amount of luck landed me my first job in Data Science in May 2019. It was a successful service based advertising startup- with a small Data team, but nevertheless I was thrilled at getting a Data Scientist role as a fresher, which was quite rare from what I had seen in the job market at that time. So I did not wait around and apply to the other jobs and took the deal.
Starting a new life and a first job in a different city looked more exciting than scary to me. My first few months were spent in understanding the requirements of the company, cleaning and understanding the code left by people before me(the aftermath of bad coding practises) and thinking of new solutions. I was overjoyed at the prospect of being paid to do something that I was doing for free.
Soon joined by another new hire, we cleaned the data, sometimes collected it, ran experiments, validated the results and repeated the whole cycle again. I also experimented with new state-of-the arts in NLP and CV to see if I could use them for our use case and in a production environment. After completing a year, I summarised my learnings in this Linkedin post:
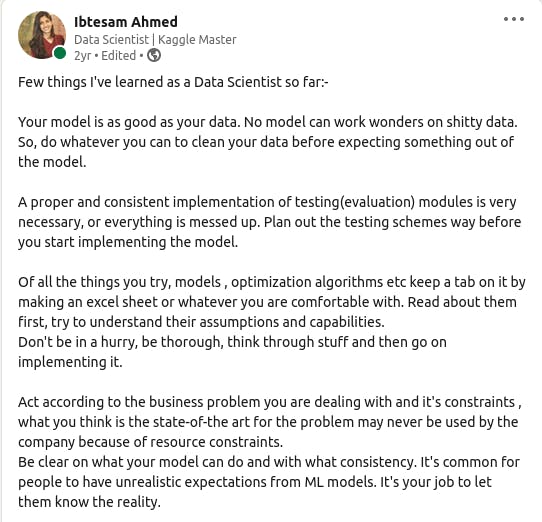
Data Science is a rapidly evolving field. To stay up-to-date I would spend a good amount of my time reading new research papers, sometimes also trying to play with a new architecture.
A new chapter
Last year in August, I joined a product based company which is doing some great work in the domain of food tech. The processes here are more structured and streamlined which leaves less room for ambiguity and frustration and more room for improvement. The data team is big and filled with talented and hardworking people. Along with the usual experiments with data and models, I work on writing good quality, optimised production grade code(which I hope my teammates would also agree to), running docker services, extensively using git and VS code, working with SQL databases, collaborating with teams and most importantly working in a fast paced environment.
All of this is still pretty new to me and it feels like starting all over again. There are days I feel overwhelmed and think I don’t deserve to be here. But then I remind myself of something a friend said -
“ As long as I am the dumbest person in the room, I get to learn the most”.
I am sure it was phrased better.
I hope this role will make me a better Software engineer besides making me a better Data Scientist. As the saying goes
“It’s easier for a Software Engineer to learn Data Science than for a Data Scientist to learn good Software Engineering“.
What do I do outside of work?
As much as I love doing what I do for a living, I also feel your 9-5 job should not define you. In the words of some data fanatics, “I (don’t) live and breath Data”, I like to have a balanced life. I work as a freelance writer. I have always been an avid reader, some of my favourite books include To Kill a Mockingbird by Harper Lee, Notes from underground by Dostoevsky, The sense of an ending by Julian Barnes, Becoming by Michelle Obama and Girl Decoded by Rana el Kaliouby.
Surprisingly, in Covid I also made a resolution to travel more, explore more cultures and hear new stories. Also in Covid, I developed a new love for cooking, as it helps me relax. A lot of my free time is spent in listening to podcasts such as Lex Fridman for conversations related to tech, AI and philosophy, Huberman Lab for science based tools for everyday life, and The Jordan B Peterson podcast for philosophy, ethics and human pyschology.
If you have made it till here, I am sure you would be happy to know that this year I intend to engage more actively with the community. Learn more tech and non-tech things and share it with everyone. This article is my first step towards that goal, I hope you’ll like it.
I am always eager to hear your thoughts, you can comment down or DM me on Twitter or Linkedin.